Welcome to RepoDB
A production-ready data access platform for .NET applications.
Get started now View it on GitHub
RepoDB is a high-performance, open-source data productivity platform for .NET developers. At its core is the RepoDB ORM—a fast, lightweight, and hybrid data access library that will always remain free and open source, and the foundation of the growing RepoDB ecosystem of tools for building, operating, and scaling enterprise applications.
Whether you’re processing millions of records, integrating multiple data sources, or preparing your systems for AI-driven development, RepoDB gives you the flexibility to work the way you want—all through the familiar IDbConnection interface. Write raw SQL when you need absolute control, use fluent APIs when productivity matters, and switch seamlessly between both without sacrificing performance or maintainability.
Why RepoDB?
As a hybrid ORM, RepoDB gives you the raw performance and control of manual data access with the convenience of a full-featured library.
| Feature | Description |
|---|---|
| Easy to Use | All operations are extension methods on IDbConnection. Open a connection and you’re ready to go. |
| High Performance | Compiled expressions are cached and reused. RepoDB understands your schema to generate the most efficient execution path ahead of time. |
| Memory Efficient | Object properties, execution contexts, mappings, and SQL statements are extracted once and reused throughout the lifetime of your application. |
| Hybrid by Design | Use fluent methods for everyday CRUD, drop down to raw SQL for complex queries, or mix both — all within the same connection. |
| Battle-Tested | Backed by thousands of unit and integration tests, and used in production systems worldwide. |
| Always Free | Apache 2.0 licensed, forever open source. |
As a productivity platform, RepoDB goes beyond the ORM with enterprise-grade capabilities that help developers build, operate, and scale with confidence.
| Feature | Description |
|---|---|
| Enterprise-Grade Bulk Operations | Perform high-performance bulk inserts, updates, merges, and deletes designed for demanding production workloads. |
| Data Replication & Integration (Planned) | Build scalable data movement and synchronization solutions across multiple database platforms. |
| Default Telemetry with Insights | Gain immediate visibility into database operations, execution times, failures, and application behavior with minimal configuration. |
| Multi-Database Ecosystem | Support a growing range of relational database providers with a consistent development experience. |
| Enterprise Ready | Designed for performance, scalability, observability, and long-term maintainability. |
| AI-Ready Architecture (Planned) | Built to integrate naturally with AI-assisted development, intelligent analytics, and future automation capabilities. |
Default Telemetry
We are excited to announce the availability of the Telemetry feature of RepoDB — a free, powerful capability that lets you observe exactly what your application is doing under the hood.
We will set it up for you in a minute! Visit our detailed tutorial from blogging site - Getting Started with RepoDB Insights Default Telemetry.
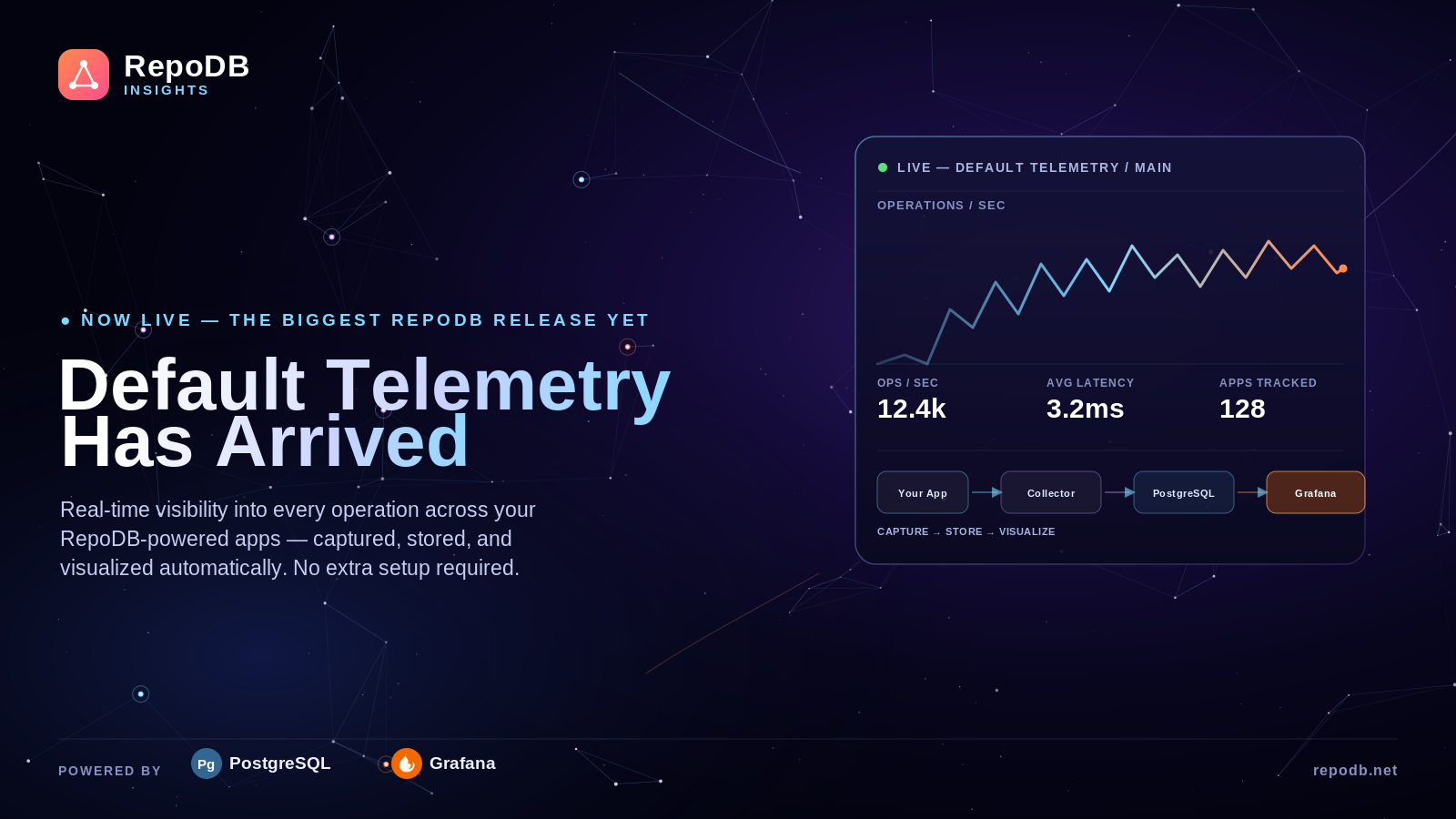
It’s part of the ecosystem we’re building around RepoDB for observing and monitoring the data pipelines that depend on the library. You no longer have to guess how your data layer is behaving — Telemetry gives developers direct visibility into what’s happening behind the scenes.
We’re shipping this capability because we believe observability is a key differentiator for a modern ORM, and a vital piece of infrastructure for data pipelines and any application that depends on reliable data access.
In this initial release, we’re publishing the Default Telemetry capability, which captures key metrics from your application and sends them to a self-hosted insights solution that runs entirely within your own environment.
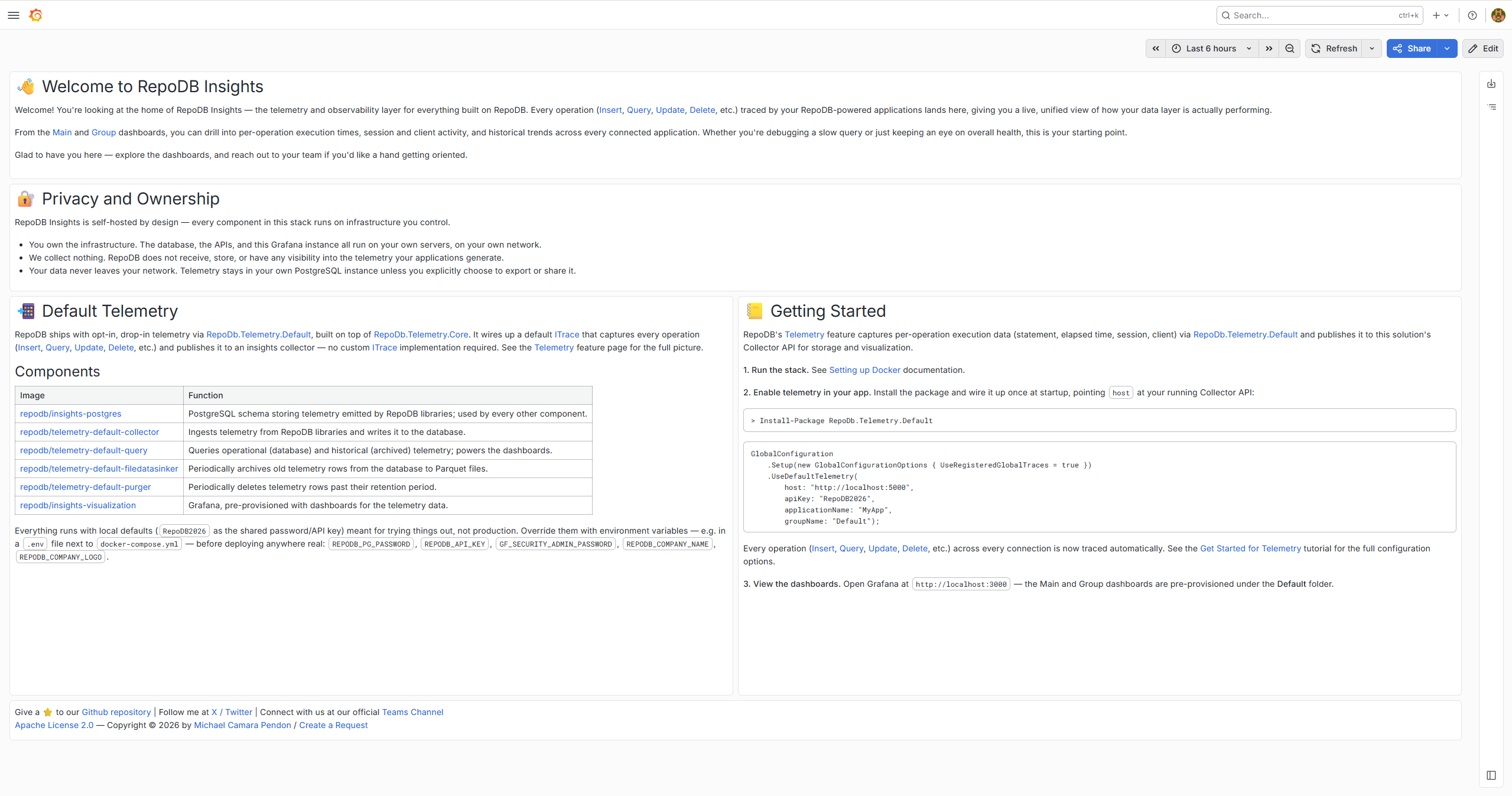
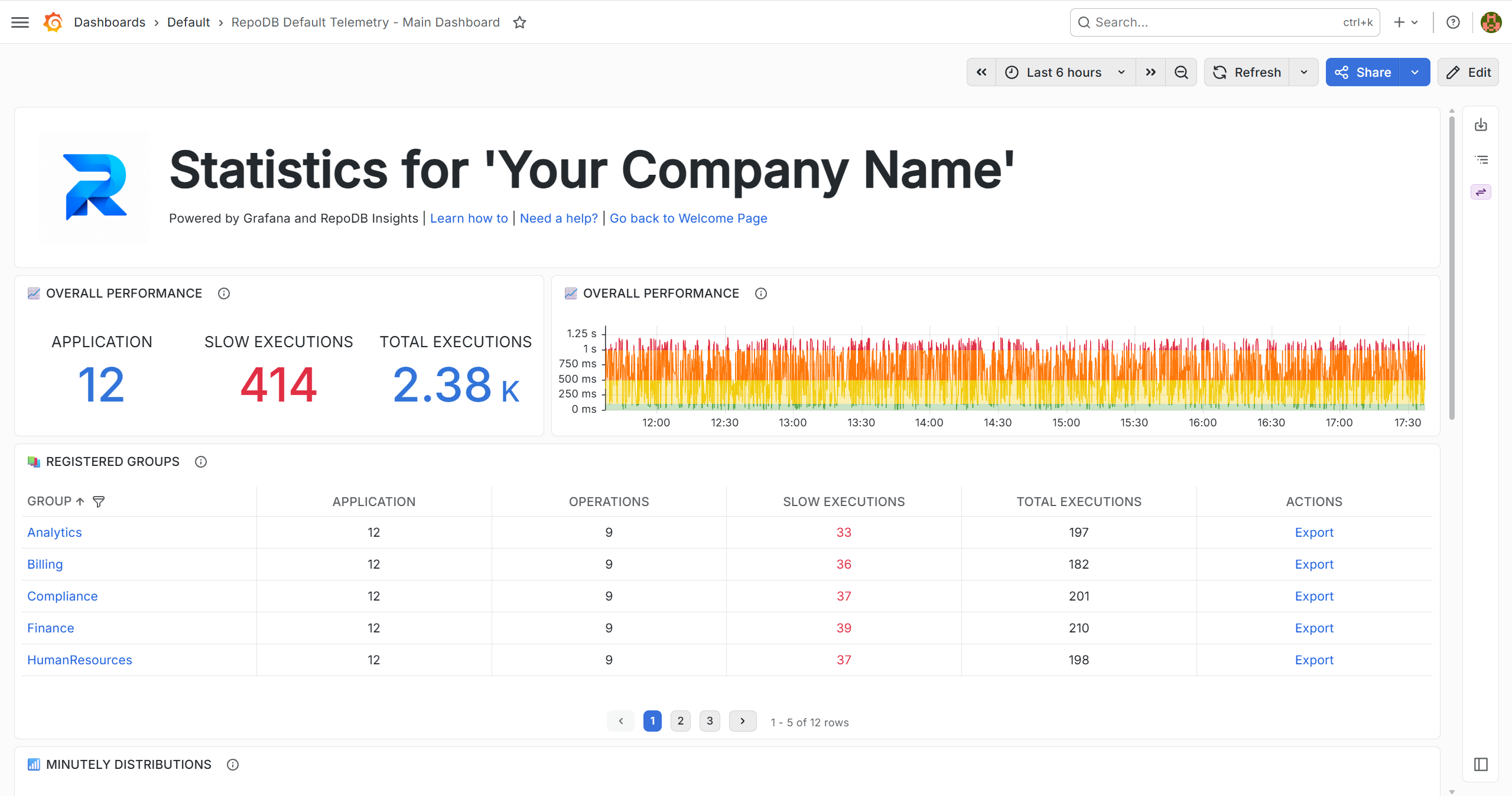
Build with confidence, without the overhead of wiring up your own instrumentation — and without worrying about where your data ends up. It’s free to use.
RepoDB’s Telemetry feature captures per-operation execution data (statement, elapsed time, session, client) via RepoDb.Telemetry.Default and publishes it to this solution’s Collector API for storage and visualization.
Getting Started
Choose a database to get started quickly:
For setup instructions, visit the installation page. For a full topic index, visit the docs page.
Report issues by creating a bug directly in our GitHub repository.